2026.06.17
Claude Code 真正厉害的地方,不是“会写代码”,而是它外面那层工程壳
目录

未来我们判断一个 Agent 产品强不强,不能只问它用了哪个模型,也不能只看 demo 里能不能跑通任务。
更应该问:当它连续工作十轮、一百轮,接入几十个工具,面对真实代码库和真实权限风险时,它还能不能稳定、可控、可审计地完成任务?
这才是 Agent 从玩具走向基础设施的分水岭。
表面上看,Claude Code 的亮点是“Claude 模型很强”。但一篇题为《Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems》的论文提醒我们:如果只盯着模型能力,就会错过 Claude Code 真正值得研究的地方。
它真正复杂、真正有壁垒的部分,不在模型本身,而在模型外面那一整套工程系统。
Claude Code 不是“一个会写代码的大模型”,而是“一个把大模型包在安全、权限、上下文、工具和持久化机制里的本地编程代理系统”。
AI Agent,拼的可能不只是模型谁更聪明,而是谁更会把聪明的模型放进一个可靠、可控、可扩展的执行环境里。
一、Claude Code 的核心循环,其实非常简单
论文拆解 Claude Code 源码后发现,它的核心 agent loop 并没有想象中复杂。
用户提出一个任务,比如:
“修一下 auth.test.ts 里失败的测试。”
Claude Code 大致会这样运行:
先组装当前上下文,包括项目状态、历史对话、相关文件、系统提示词和可用工具;
然后调用 Claude 模型,让模型判断下一步该做什么;
如果模型提出工具调用,比如读文件、搜索代码、运行测试或修改文件,系统会把这个工具调用交给权限系统检查;
通过之后才真正执行工具;工具执行结果再作为新上下文返回给模型;
模型继续判断下一步,直到它不再调用工具,而是给出最终回复。
这就是一个循环:调用模型,执行工具,拿到结果,再调用模型。
这个循环可以说很朴素。但 Claude Code 的关键不在这个循环本身,而在循环周围的“基础设施”。
论文里有一个很有意思的判断:Claude Code 里真正属于 AI 决策逻辑的部分很薄,大部分代码都在处理模型之外的问题。
比如工具怎么注册,权限怎么判断,shell 命令怎么隔离,历史上下文怎么压缩,子任务怎么委托,会话怎么恢复,用户怎么审批,插件怎么接入。
这也解释了为什么很多人照着 ReAct 或 tool calling 写一个 demo 很快,但要做成 Claude Code 这种生产级工具却非常难。
demo 里的 Agent 只要“能跑”就行;生产级 Agent 必须“跑错了也不能太危险,跑久了也不能崩,接入更多工具后也不能失控”。
二、Claude Code 的第一性问题:模型不能直接碰世界
Claude Code 架构里一个非常关键的分离是:模型负责判断“想做什么”,但不能直接执行动作。
Claude 模型不会直接访问文件系统,也不会直接跑 shell,更不会绕过系统去访问网络。
模型只能输出结构化的 tool_use 请求,例如“我要读这个文件”“我要执行这个命令”“我要编辑这一段代码”。真正执行动作的是 Claude Code 外部的 harness,也就是那层工程壳。
这个设计看似普通,其实是 AI Agent 安全性的基础。

如果模型自己能直接碰文件系统,那模型一旦被 prompt injection、错误推理或恶意上下文诱导,就可能直接产生破坏性后果。但在 Claude Code 里,模型只是“提议动作”。每一个动作都必须经过系统层面的权限判断、规则匹配、hook 拦截,必要时还要让用户确认,shell 命令还可能进入 sandbox。
这就形成了一种分权结构:模型有智能,但没有最终执行权;系统有执行权,但必须按规则办事;用户保留关键决策权。
这也是 Claude Code 跟很多玩具级 Agent 的区别。玩具级 Agent 常常把模型输出直接接到执行器上,看起来很酷,但本质上是“模型说什么就做什么”。Claude Code 更像一个严谨的操作系统接口:模型可以申请调用系统资源,但不能绕过内核。
三、权限系统才是 Claude Code 的灵魂之一
论文花了大量篇幅分析 Claude Code 的权限系统,因为这是生产级编程代理最核心的问题之一:当 AI 可以改代码、删文件、跑命令的时候,什么能自动执行,什么必须问用户,什么永远不能执行?
Claude Code 采用的是 deny-first,也就是“拒绝优先”的策略。
简单说,deny 规则优先级最高,其次是 ask,最后才是 allow。即便某个动作看起来被 allow 规则允许,只要它命中了 deny 规则,也不能执行。未知动作也不会默认放行,而是升级给用户确认。
这跟很多人想象中的“智能体越自动越好”不同。Claude Code 的设计哲学不是无脑放权,而是逐步建立信任。
它有多种权限模式:有偏保守的 plan 模式,也有默认交互模式,有自动接受编辑的 acceptEdits 模式,还有更激进的 bypassPermissions 模式。用户可以随着信任增加,逐步放开权限。但即使在更宽松的模式下,某些安全关键规则仍然不能轻易绕过。
这背后有一个现实问题:用户其实并不擅长长期认真审批。

论文引用的 Anthropic 相关观察提到,用户会批准大部分权限请求。也就是说,如果系统只是每次弹窗问“是否允许”,用户很快就会疲劳,最后变成机械地点“同意”。这时,表面上保留了人的控制权,实际上安全性已经下降。
所以 Claude Code 的策略不是把所有安全责任都甩给用户,而是做分层防御:规则系统先过滤,权限模式设定基本边界,自动分类器判断风险,hook 可以拦截,shell sandbox 进一步隔离。任何一层发现问题,都可以阻止执行。
这就是 AI Agent 从“能用”到“可信”的关键变化:不要假设用户会永远警觉,系统自己必须有安全骨架。
四、上下文窗口,是 Claude Code 真正稀缺的资源
很多人讨论 AI 编程工具时,喜欢问模型支持多少 token。Claude Code 的架构给出的答案是:上下文窗口越大越好,但再大也不够用。
因为一个真实代码任务里,上下文会快速膨胀。用户的原始需求、项目说明、CLAUDE.md、历史对话、读取过的文件、测试输出、报错日志、工具调用结果、子代理摘要,都会进入上下文。如果不管理,模型很快会被无关信息淹没,或者直接超出上下文窗口。
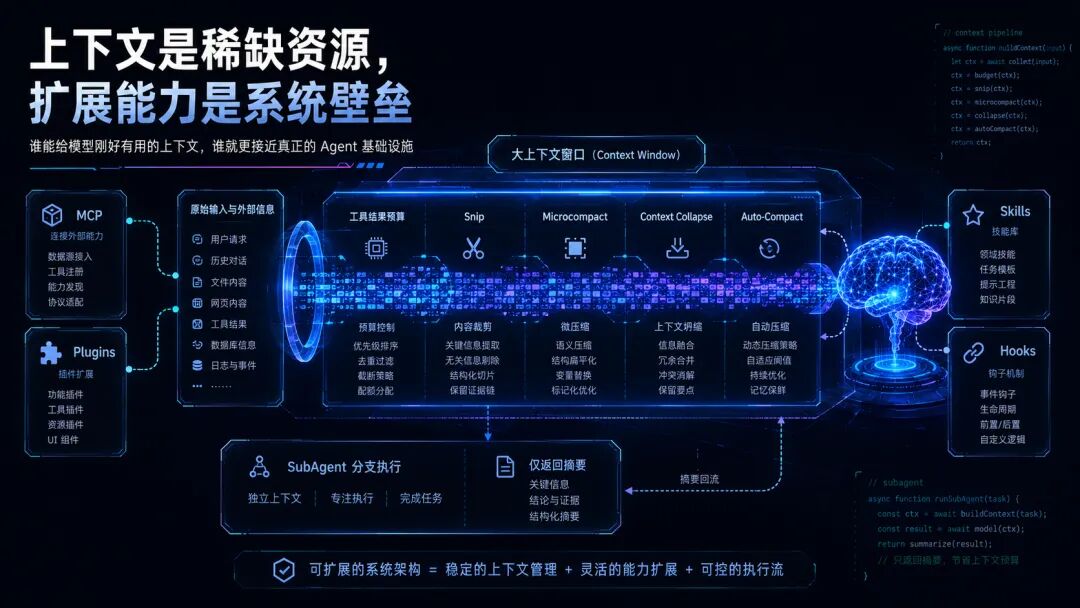
Claude Code 因此设计了一套多层上下文管理机制。
它不是简单地“超过长度就截断”,而是分层处理:先限制单个工具结果的大小,避免一个超长日志占满窗口;再剪掉较早的历史片段;再做更细粒度的 microcompact;必要时做 context collapse,把长历史折叠成可读摘要;最后才用模型生成整体压缩摘要,也就是 auto-compact。
上下文不是垃圾桶,不能什么都塞进去;上下文是昂贵资源,要像内存、CPU、磁盘一样被调度。
这也是 Claude Code 的一个重要启发。未来 Agent 的能力,不只取决于模型单次推理多强,还取决于系统能否持续给模型提供“刚好有用”的上下文。
给少了,模型不知道项目真实情况;给多了,模型被噪音干扰;给错了,模型会朝错误方向努力。上下文工程会成为 Agent 产品的核心竞争力。
五、Claude Code 为什么要有 MCP、插件、技能和 hooks 四套扩展机制?
如果只是做一个简单工具,扩展机制可以很粗暴:所有能力都做成 tool,注册给模型就行。
但 Claude Code 没有这么做。论文指出,它有四类扩展机制:MCP、plugins、skills 和 hooks。
MCP 主要负责连接外部工具和服务,比如数据库、文档系统、远程 API、内部平台。它让 Claude Code 可以把外部能力变成模型可调用的工具。
Plugins 更像分发和打包机制,一个插件可以同时带来 commands、agents、skills、hooks、MCP servers、settings 等组件。它解决的是“如何把一组能力交付给用户”的问题。
Skills 则更像领域知识包。一个 skill 可以告诉 Claude 在某个特定任务里应该怎么想、怎么调用工具、遵循什么约束。它不是简单增加一个工具,而是给模型注入某种工作方式。
Hooks 是生命周期拦截器。它可以在工具调用前后、会话开始结束、权限请求、文件变化、上下文压缩等事件上运行逻辑。它默认不需要占用模型上下文,却能改变系统行为。
这四套机制看起来复杂,但背后有一个清晰逻辑:不同扩展方式的上下文成本不同。
MCP 工具需要把工具 schema 暴露给模型,成本较高;skills 通常只暴露描述,成本较低;hooks 默认几乎不占上下文,因为它们在系统侧运行;plugins 则负责把这些机制打包分发。
这说明 Claude Code 的扩展设计不是“越统一越好”,而是按成本和用途分层。对 Agent 系统来说,扩展机制不仅是 API 设计问题,也是上下文预算问题。
六、子代理不是炫技,而是上下文隔离
Claude Code 还有一个重要机制:subagent,也就是子代理。
当主代理遇到复杂任务时,可以派生子代理去做某个局部工作,比如探索代码结构、调查某个 bug、执行一个独立分析。子代理有自己的上下文窗口、自己的工具集合和执行过程。
它完成任务后,不会把完整过程全部塞回主代理,而是只返回摘要。
如果子代理把所有中间文件读取、命令输出和推理过程都返回给主代理,主上下文很快就会爆炸。Claude Code 的做法是让子代理独立消耗上下文,只把结果浓缩后交回主流程。同时,子代理的完整过程会单独保存,便于之后审计和恢复。
这是一种很实用的多代理架构。它不是为了制造一群“会聊天的智能体”,而是为了做任务隔离、上下文隔离和职责隔离。
换句话说,Claude Code 的 subagent 更像操作系统里的子进程,而不是微信群里的多个 AI 角色。
七、Claude Code 和 OpenClaw 的差异:Agent 没有唯一正确架构
论文还把 Claude Code 和 OpenClaw 做了对比。这个对比很有价值,因为它说明:Agent 系统没有唯一正确架构,架构答案取决于部署环境。
Claude Code 是一个面向代码仓库、终端和开发者工作流的编程代理。
它的核心问题是:AI 如何安全地在本地项目里读写文件、执行命令、修复代码?所以它把大量设计放在每个动作的权限判断、上下文压缩、shell 执行、安全边界和会话恢复上。
OpenClaw 则更像一个多渠道个人助理网关。它面对的是邮件、消息、日历、外部服务等更广泛场景。因此它更强调网关层的身份、访问控制、能力注册、跨渠道路由和长期记忆。
同样是 Agent,一个像“命令行里的工程师”,一个像“个人助理入口”。它们面对的问题类似:安全边界在哪里,工具怎么接入,状态怎么保存,用户怎么控制。但由于应用场景不同,答案完全不同。
不要用一个 Agent 框架解释所有问题。写代码的 Agent、办公助理 Agent、浏览器 Agent、客服 Agent、数据分析 Agent,真正的架构差异可能远大于表面上的“都能调用工具”。
八、这篇论文最值得注意的批判:AI 会不会让人变弱?
论文最后提出了一个很重的问题:Claude Code 这样的系统显著放大了人的短期能力,但它未必能帮助人保持长期能力。
当 AI 帮你读代码、改代码、跑测试、解释错误、生成方案时,你的短期产出肯定变高。但长期看,如果开发者越来越少亲自理解代码库,越来越少经历调试细节,越来越依赖 AI 给出的判断,那么他监督 AI 的能力会不会下降?
这就是所谓“监督悖论”:
你越依赖 AI,
越需要有能力监督 AI;
但越依赖 AI,
你自己的监督能力可能越退化。
Claude Code 当前的架构主要服务于短期能力放大,让用户更快完成任务,但它并没有特别强的机制去保证用户长期理解力、代码库整体认知和工程判断能力不下降。
未来的 AI 编程工具,可能需要把“帮助人变强”也变成产品目标,而不只是“替人做得更多”。
例如,系统可以在完成任务后解释关键决策,可以要求用户审阅高风险变更,可以生成学习型 diff,总结代码库模式,也可以在长期项目里维护架构一致性报告。否则,Agent 可能会让个体开发者短期更强,但让团队长期理解能力变弱。
九、真正的竞争,会发生在模型之外
读完这篇论文,最大的感受是:AI Agent 的竞争正在从“模型能力竞争”走向“系统能力竞争”。
模型当然重要。没有强模型,Claude Code 这种工具不可能成立。但当模型能力逐渐接近,真正拉开差距的会是模型外部的系统设计。
一个好的 Agent 系统,至少要回答这些问题:
模型能看到什么上下文?
模型能调用哪些工具?
哪些动作可以自动执行,哪些必须审批?
如果用户一直点同意,系统还能不能保护他?
工具调用失败后,模型怎么恢复?
上下文爆了,应该丢什么、压缩什么、保留什么?
扩展能力怎么接入,又如何避免工具 schema 把上下文撑爆?
子任务如何隔离,结果如何汇总?
会话如何恢复、审计和回滚?
模型和环境的关系是什么?
这些问题都不是单纯靠一个更强的大模型解决的。它们是产品问题、工程问题、安全问题,也是组织信任问题。
Claude Code 给出了一个生产级答案:用一个简单的 agent loop 承载模型推理,用复杂但清晰的工程外壳管理执行世界。
Claude Code 是是一个小型的“AI 操作系统”:模型是其中的智能内核之一,让它能安全工作的是权限、工具、上下文、扩展、隔离和持久化组成的系统层。
未来我们判断一个 Agent 产品强不强,不能只问它用了哪个模型,也不能只看 demo 里能不能跑通任务。
更应该问:当它连续工作十轮、一百轮,接入几十个工具,面对真实代码库和真实权限风险时,它还能不能稳定、可控、可审计地完成任务?
这才是 Agent 从玩具走向基础设施的分水岭。
原文链接:https://mp.weixin.qq.com/s/2KQkT9l07BrGYaogYgiyHA
来源:XT
相关文章
- AI越强,对于人对方向和价值的敏锐度要求越高。提示词工程作为“怎么把话说给模型听”的技巧,重要性在下降;但它背后真正有价值的东西没有下降,反而更重要了:判断力、问题定义能力、审美品味、以…
- 机器学习项目的真实面貌:训练只占2%,数据与评估才是王道训练模型固然重要,但它只是整个 pipeline 的最后一环,而且占比极小。真正决定项目成败的,是前面的评估和数据工作。 最近,Tesla…
- 这里有10组动词,让你精准驾驭与AI的对话。除了使用“为什么、是什么、如何做”这些常见的提问方式以外,你可以更主动地采用“动词”——这正是驾驭AI的关键。 这里是我与AI对话的“动词工…
- “死磕、加速、杠杆、乐趣、与能力退化 ”—— Andrej Kaparthy 这几周的AI Coding的笔记过去几周大量使用 Claude 编码的一些随机笔记 编码工作流 得益于 LLM 编码能力的最近大幅提升,和很多人一样,我在11月份还是大约8…