2025.06.07
AI Agent的评估框架

建立AI Agent,是为了解决问题,发挥大语言模型的价值,由于LLM的特性,AI Agent的有效性很难在设计之初有准确预判,它的提升是一个渐进过程,所以agent开发时,边评估,边优化,比传统软件开发测试,显得更为重要。
AI agent的评估框架
如果你无法评估你的Agent应用,或者评估成本高、周期长的Agent,那就不必花太多心思。
产品经理需要把关注力投入到那些具体的、可以建立快速评估体系的Agent应用方向上去。
评估AI agent确实是个复杂话题。Agent的“智能化”是相对的,比如医疗agent和游戏agent的评估维度就完全不同。
脱离应用场景的衡量评估方法,只能泛泛而谈。评估AI Agent,有4个核心评估维度 (能力、效率、健壮性、安全性):
- 能力与效果 :
Agent是否能正确、成功地完成任务?
指标: 任务完成率、目标达成度、准确率、召回率、F1分数、成功率、人类专家评分、输出质量(相关性、完整性、创造性)。
- 效率与性能 :
Agent完成任务的成本(时间、计算资源等)是多少?
指标: 响应延迟/时间、推理步骤数、计算资源消耗(CPU、GPU、内存、带宽)、Token消耗量、成本(每次推理/任务)。
- 健壮性与可靠性:
Agent在面对干扰、意外输入或环境变化时表现如何?它是否稳定可靠?
指标: 错误率、失败率、对噪声/模糊输入/分布外数据的鲁棒性、在动态变化环境中的稳定性、容错能力、平均无故障运行时间。
- 安全性与对齐:
Agent的行为是否符合人类价值观、伦理准则、安全规范和应用场景要求?是否存在有害或偏见输出?
指标: 检测到有毒语言/偏见/幻觉的比例、遵守指令/安全护栏的程度、对抗性攻击下的安全性、对价值观对齐(无害性、诚实性、有益性)的量化评估、责任归属清晰度。
关键评估步骤 (Key Steps):
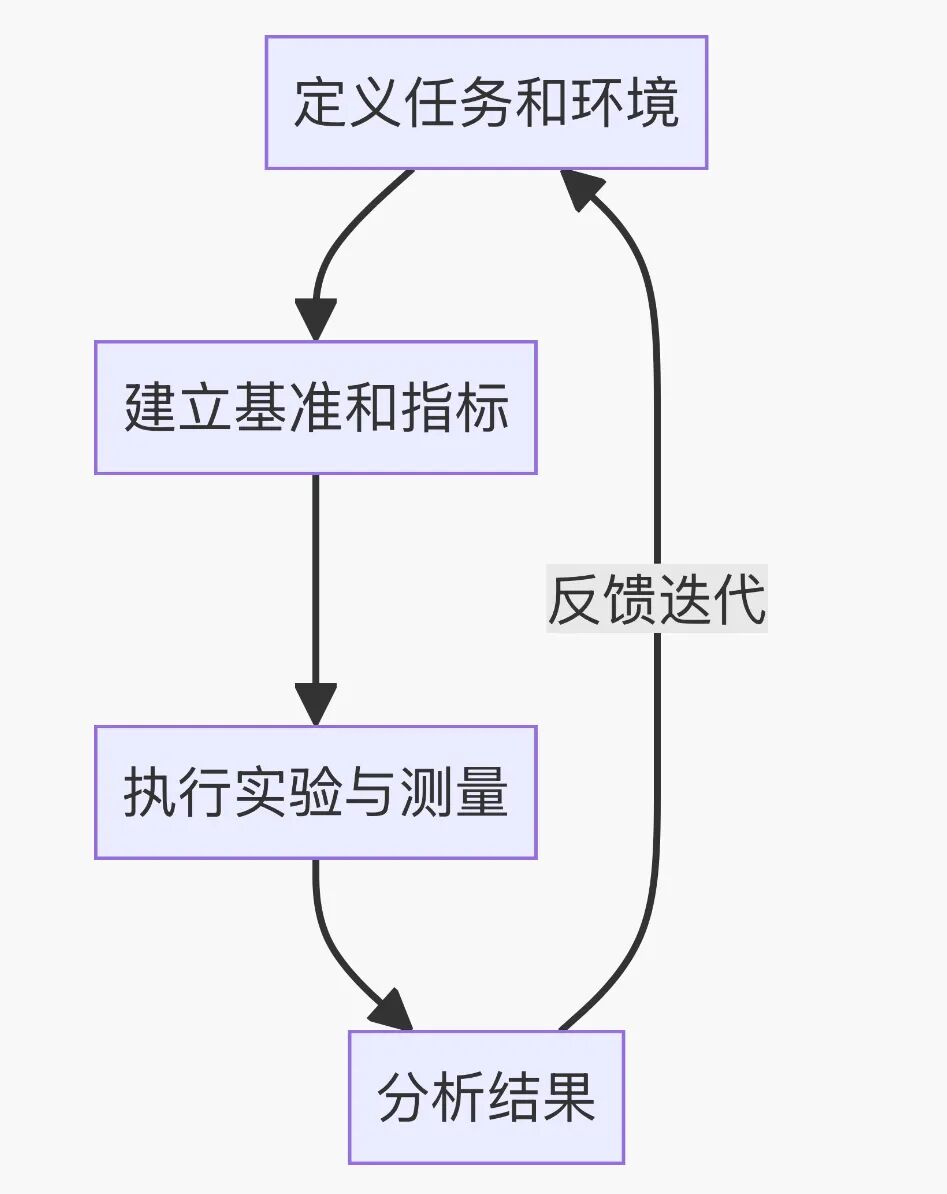
- 明确定义任务和环境:
清晰描述Agent需要解决的具体问题(目标、输入、期望输出)。详细说明其运行的模拟或真实环境(状态空间、行动空间、可获取信息、约束条件)。
- 建立评估基准和指标:
a. 标准答案 (Ground Truth): 如果可能,获取测试输入对应的标准正确答案。
b. 测试数据集/场景: 准备覆盖性强的测试数据集、典型用例、边缘用例、对抗性场景。
c. 量化指标: 根据上述核心维度选择合适的、可量化的指标(如准确率、延迟时间、失败率等)。
d. 定性评估: 设计人类评估环节,评价输出的质量、流畅度、有用性、安全性(尤其在自然语言交互或创意任务中)。
- 执行实验与测量:
在定义好的测试环境和场景中运行Agent。收集Agent的输出、行为轨迹、资源消耗等数据。
对照标准答案(如果有)计算定量指标。收集人类评估者的反馈(如果需要)。
- 分析结果与反馈迭代:
汇总所有定量和定性数据。识别Agent的优势和弱点(例如,在特定任务上表现优异,但在边缘案例或效率上不足)。
- 评估安全性和伦理风险。
根据分析结果,提供反馈用于改进Agent的设计(如Prompt优化、模型微调、流程调整)或环境适配(如提供更清晰的信息)。
Agent的学习能力,意味着评估不应是一次性的,需要持续监控其在真实部署中的表现(性能漂移、新风险)。
结合客观指标和主观人类评价(尤其在衡量“质量”、“有用性”、“安全性”时)是非常必要的。
原文链接:https://mp.weixin.qq.com/s/WZDeh8Q_H8nteAEpmpdaWQ
来源:XT
相关文章
- AI Agent产品经理的关键技能AI Agent设计,旨在通过感知环境,并利用LLM规划调用工具,采取行动实现特定目标。 Agent的核心在于其推理、逻辑以及访问外部信息的…
- 速览:AI Agent智能体软件的10种分类,以及典型代表。AI Agent 智能体软件的分类维度多样,实际开发中,需要结合多个角度进行设计。将智能体分类,目的是更好地理解 Agent 的能力边界与适…
- Agent设计中,PRD不只是文档,而是“代码”,是上下文,是功能本身。Agent开发过程中,PRD不只是文档,而是“代码”,是上下文,是功能本身。 传统软件开发,和AI Agent开发范式差异巨大。这一点,在P…
- AI Agent的基本模块AI Agent的设计高度依赖场景,一个AI Agent(智能体)的核心要素可以抽象为感知、决策、行动的闭环,以下是其最基本的骨架。 感知模…